
GOAL
- VGGNet의 구조를 이해
- Tensorflow를 이용하여 VGG16으로 CIFAR10 데이터셋을 이용하여 분류해 보자
VGGNet
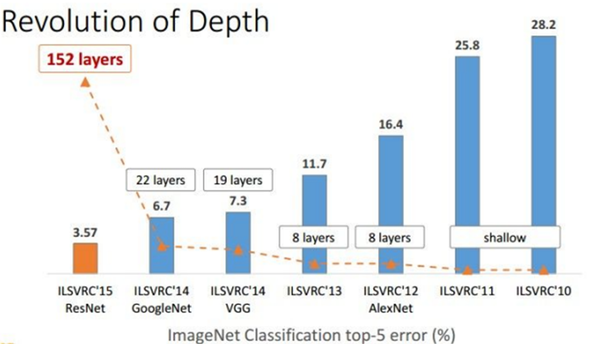
- VGGNet은 2014년 ILSVRC에서 2위를 한 Oxford 대학교의 VGGNet 팀에서 만든 모델입니다.
- 구조적인 측면에서 굉장히 간단한데 성능은 훌륭하며 변형을 시켜가면서 테스트하기에 좋아 많이 사용되고 있습니다.
- AlexNet과 무엇이 다른지 확인하고 VGGNet16을 구현해 보도록 하겠습니다.
네트워크의 깊이(depth)
- 앞서 설명한 AlexNet의 Layer의 수는 8개였습니다. 그에 비해 VGGNet16은 Layers수가 16개로 더 깊어진 것을 볼 수 있습니다.
- 망이 깊어지면 출력단에서 하나의 픽셀이 담고 있는 정보의 양이 많아지며 훨씬 복잡한 문제를 풀 수 있게 됩니다.
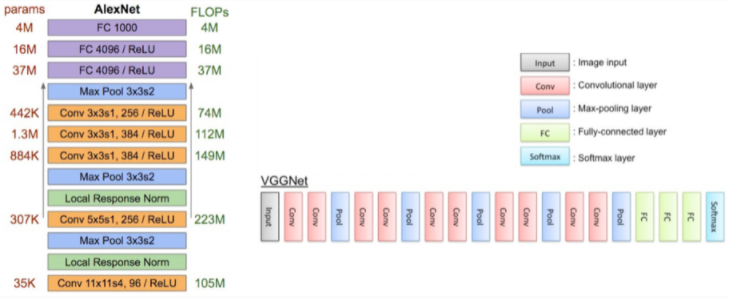
- 구조는 AlexNet과 크게 다르지 않지만 확실하게 깊이에서 차이가 나는 것을 볼 수 있습니다.
망을 깊이 했을 때 문제점?
- 그렇다면 깊게 했을 때 이점만 있을까요? 망이 깊어지면 문제점이 생길 수도 있습니다
성능을 올릴 수 있지만 자유 파라미터(free parameter)의 수가 증가하게 되면서 overfitting에 빠질 가능성이 높아지며
연산량이 증가하여 학습 시간이 오래 걸린다는 단점이 있습니다.
VGGNet 구조
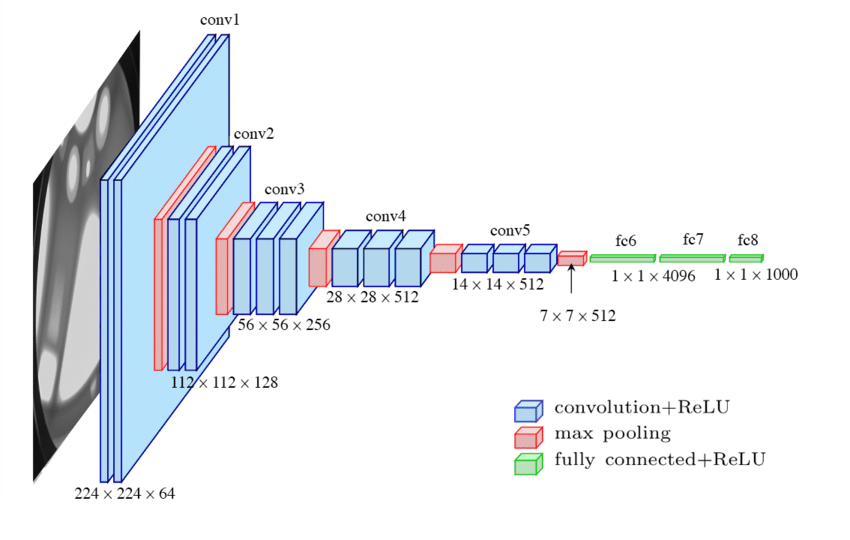
- VGGNet 논문에서는 오로지 깊이가 주는 영향력을 알기 위해 필터는 3x3으로 stride는 1로 고정했으며
MaxPooling은 2x2에 stride 2로 하여 학습을 진행했습니다.
- VGG 팀은 여러 가지 방법으로 테스트를 진행했다고 합니다.
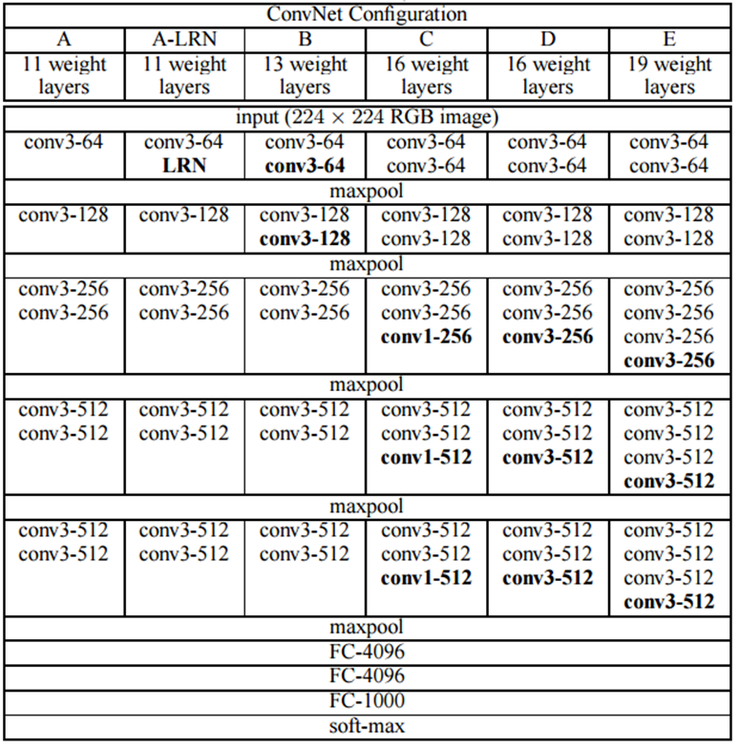
- 위 표에서 보이는 것처럼 input을 224x224x3으로 입력받아 Conv와 Maxpool을 반복하다가 fully-connected layer를 연결하는 구조로 만들었는 걸 볼 수 있고 테스트마다 Conv의 개수를 다르게 했다는 것을 알 수 있습니다.
- AlexNet과 다르게 LRN을 쓰지 않았으며 3x3 필터만을 사용하여 학습시키는 것이 가장 큰 특징입니다.
Tensorflow로 VGGNet16을 구현하고 CIFAR10 데이터셋 분류
- AlexNet에서 했던 CIFAR10 데이터 셋을 로드하고 전처리했던 부분을 그대로 가져와서 사용했습니다.
- VGGNet 모델링
model = Sequential()
# model.add(layers.experimental.preprocessing.Resizing(224, 224, interpolation="bilinear", input_shape=x_train.shape[1:]))
model.add(Conv2D(64, 3, strides= 1, padding='same', input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(64, 3, strides= 1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2,2), strides=2))
model.add(Conv2D(128, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(128, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
- model.summary() 결과

- AlexNet에서 32x32 크기의 CIFAR10 데이터 셋을 227x227로 resize 해서 input을 넣었지만 혹시나 upsampling 과정에서 발생하는 noise 때문에 학습이 제대로 안 됐을까 봐 이번에는 데이터 셋을 그대로 input으로 넣었습니다.
- 결과
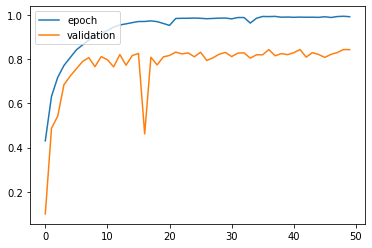
Test loss: 1.5999219417572021
Test accuracy: 0.8429999947547913
- AlexNet과 크게 차이가 없는데 이유를 모르겠습니다..
자꾸만 과적합 되네요 혹시 아시는 분은 댓글로 알려주세요 ㅠㅠ
추가 내용(2024-02-07) : VGGNet과 AlexNet의 성능 차이가 크게 나지 않은 이유
- 댓글로 질문에 주셔서 내용에 추가합니다.
VGGNet과 AlexNet의 성능 차이가 크지 않은 이유를 저는 주로 CIFAR 10의 데이터셋의 특성과 관계가 있다 생각합니다.
CIFAR 10은 상대적으로 간단한 데이터셋이며
이미지의 크기가 32x32로 상당히 작고 클래스 수도 10개로 제한되어 있습니다.
이런 간단한 데이터셋에서는 복잡한 모델이 반드시 더 나은 결과를 가져오지는 않습니다.
또한 CIFAR 10의 32x32 이미지를 227x227로 확대하면
원래의 고해상도 정보가 손실되고 모델에 성능에 영향을 미칩니다.
두 모델 모두 데이터셋에 대해 특별한 튜닝 없이 사용했으므로 성능 차이가 크지 않을 수도 있다고 생각합니다.
그래서 VGGNet의 성능을 향상하려면 어떻게 해야 할까?라고 한다면 여러 가지를 생각해 볼 수 있습니다.
- 데이터셋 전처리
- 하이퍼파라미터 튜닝
- 옵티마이저 변경
- 앙상블 학습
위 방법들은 VGGNet 뿐만 아니라 다른 모델의 성능을 향상할 수 있습니다.
이번 포스팅은 VGGNet을 이해하고 구현까지 해보았습니다
혹시나 틀린 점이나 질문이 있으시면 댓글로 남겨주세요!
감사합니다 :)
'AI > DL' 카테고리의 다른 글
| Batch Normalization (배치 정규화) 이해 (0) | 2021.08.29 |
|---|---|
| ResNet 구조 이해 및 구현 (4) | 2021.08.25 |
| AlexNet 구조 이해 및 구현 (2) | 2021.08.19 |
GOAL
- VGGNet의 구조를 이해
- Tensorflow를 이용하여 VGG16으로 CIFAR10 데이터셋을 이용하여 분류해 보자
VGGNet
- VGGNet은 2014년 ILSVRC에서 2위를 한 Oxford 대학교의 VGGNet 팀에서 만든 모델입니다.
- 구조적인 측면에서 굉장히 간단한데 성능은 훌륭하며 변형을 시켜가면서 테스트하기에 좋아 많이 사용되고 있습니다.
- AlexNet과 무엇이 다른지 확인하고 VGGNet16을 구현해 보도록 하겠습니다.
네트워크의 깊이(depth)
- 앞서 설명한 AlexNet의 Layer의 수는 8개였습니다. 그에 비해 VGGNet16은 Layers수가 16개로 더 깊어진 것을 볼 수 있습니다.
- 망이 깊어지면 출력단에서 하나의 픽셀이 담고 있는 정보의 양이 많아지며 훨씬 복잡한 문제를 풀 수 있게 됩니다.
- 구조는 AlexNet과 크게 다르지 않지만 확실하게 깊이에서 차이가 나는 것을 볼 수 있습니다.
망을 깊이 했을 때 문제점?
- 그렇다면 깊게 했을 때 이점만 있을까요? 망이 깊어지면 문제점이 생길 수도 있습니다
성능을 올릴 수 있지만 자유 파라미터(free parameter)의 수가 증가하게 되면서 overfitting에 빠질 가능성이 높아지며
연산량이 증가하여 학습 시간이 오래 걸린다는 단점이 있습니다.
VGGNet 구조
- VGGNet 논문에서는 오로지 깊이가 주는 영향력을 알기 위해 필터는 3x3으로 stride는 1로 고정했으며
MaxPooling은 2x2에 stride 2로 하여 학습을 진행했습니다.
- VGG 팀은 여러 가지 방법으로 테스트를 진행했다고 합니다.
- 위 표에서 보이는 것처럼 input을 224x224x3으로 입력받아 Conv와 Maxpool을 반복하다가 fully-connected layer를 연결하는 구조로 만들었는 걸 볼 수 있고 테스트마다 Conv의 개수를 다르게 했다는 것을 알 수 있습니다.
- AlexNet과 다르게 LRN을 쓰지 않았으며 3x3 필터만을 사용하여 학습시키는 것이 가장 큰 특징입니다.
Tensorflow로 VGGNet16을 구현하고 CIFAR10 데이터셋 분류
- AlexNet에서 했던 CIFAR10 데이터 셋을 로드하고 전처리했던 부분을 그대로 가져와서 사용했습니다.
- VGGNet 모델링
model = Sequential()
# model.add(layers.experimental.preprocessing.Resizing(224, 224, interpolation="bilinear", input_shape=x_train.shape[1:]))
model.add(Conv2D(64, 3, strides= 1, padding='same', input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(64, 3, strides= 1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2,2), strides=2))
model.add(Conv2D(128, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(128, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(256, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(Conv2D(512, 3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Activation(activation='relu'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(MaxPool2D((2, 2), strides=2))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
- model.summary() 결과
- AlexNet에서 32x32 크기의 CIFAR10 데이터 셋을 227x227로 resize 해서 input을 넣었지만 혹시나 upsampling 과정에서 발생하는 noise 때문에 학습이 제대로 안 됐을까 봐 이번에는 데이터 셋을 그대로 input으로 넣었습니다.
- 결과
Test loss: 1.5999219417572021
Test accuracy: 0.8429999947547913
- AlexNet과 크게 차이가 없는데 이유를 모르겠습니다..
자꾸만 과적합 되네요 혹시 아시는 분은 댓글로 알려주세요 ㅠㅠ
추가 내용(2024-02-07) : VGGNet과 AlexNet의 성능 차이가 크게 나지 않은 이유
- 댓글로 질문에 주셔서 내용에 추가합니다.
VGGNet과 AlexNet의 성능 차이가 크지 않은 이유를 저는 주로 CIFAR 10의 데이터셋의 특성과 관계가 있다 생각합니다.
CIFAR 10은 상대적으로 간단한 데이터셋이며
이미지의 크기가 32x32로 상당히 작고 클래스 수도 10개로 제한되어 있습니다.
이런 간단한 데이터셋에서는 복잡한 모델이 반드시 더 나은 결과를 가져오지는 않습니다.
또한 CIFAR 10의 32x32 이미지를 227x227로 확대하면
원래의 고해상도 정보가 손실되고 모델에 성능에 영향을 미칩니다.
두 모델 모두 데이터셋에 대해 특별한 튜닝 없이 사용했으므로 성능 차이가 크지 않을 수도 있다고 생각합니다.
그래서 VGGNet의 성능을 향상하려면 어떻게 해야 할까?라고 한다면 여러 가지를 생각해 볼 수 있습니다.
- 데이터셋 전처리
- 하이퍼파라미터 튜닝
- 옵티마이저 변경
- 앙상블 학습
위 방법들은 VGGNet 뿐만 아니라 다른 모델의 성능을 향상할 수 있습니다.
이번 포스팅은 VGGNet을 이해하고 구현까지 해보았습니다
혹시나 틀린 점이나 질문이 있으시면 댓글로 남겨주세요!
감사합니다 :)
'AI > DL' 카테고리의 다른 글
| Batch Normalization (배치 정규화) 이해 (0) | 2021.08.29 |
|---|---|
| ResNet 구조 이해 및 구현 (4) | 2021.08.25 |
| AlexNet 구조 이해 및 구현 (2) | 2021.08.19 |