
GOAL
- Alexnet의 구조를 이해
- Tensorflow를 이용하여 AlexNet으로 CIFAR10 데이터셋을 이용하여 분류해보자
AlexNet
- AlexNet은 2012년 ImageNet 데이터를 기반으로 한 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 캐나다의 토론토 대학이 차지하는데 당시 논문의 첫 번째 저자가 Alex Khrizevsky이며 이 분의 이름을 따서 AlexNet이라고 부르게 되었다.

- SuperVision이 AlexNet을 의미하며 다른 팀들과 차이가 많이 나는 것을 볼 수 있다.
- 이 대회 이후 ILSVRC에는 딥러닝을 이용한 모델들이 주를 이뤘으며 더 좋은 성능을 보이게 된다.
- 구조적 관점을 보았을 때 LeNet5와 크게 다른 점은 없지만 GPU를 사용하여 의미 있는 결과를 얻었으며 이후 CNN을 사용할 때 GPU를 사용하는 것이 대세가 되었다.
AlexNet 구조

- 위 그림과 같이 AlexNet은 5개의 convolution layers와 3개의 full-connected layers 구성되어 있다.
- 마지막 FC는 1000개의 카테고리를 분류하기 위해 softmax 함수를 사용하고 있음을 기억!
1) 첫 번째 레이어(컨볼루션)

→ Input이 224x224x3으로 되어있지만 뒤의 계산과 맞으려면 227x227x3으로 해야 한다.
→ 96개의 11x11x3 필터로 input을 컨볼루션 한다. stride를 4로 했고 padding은 사용하지 않음
→ 결과적으로 55 x 55 x 96의 feature map이 추출되었고 ReLU 함수로 활성화한다.
2) 두 번째 레이어(컨볼루션)
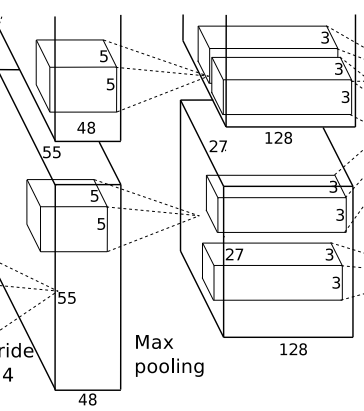
→ 256개의 5x5x96의 필터로 전 단계의 feature map을 컨볼루션 하는데 이때는 stride1로 실행했다.
→ 3 x 3 MaxPooling을 stride 2로 시행한다.
→ 3 x 3 MaxPooling을 stride2로 시행한 결과 27x27x256개의 feature 맵을 얻게 된다.
→ 역시 ReLU로 활성화한다.
3) 세 번째 레이어(컨볼루션)

→ 384개의 3x3x256의 필터를 사용하여 컨볼루션 한다. stride를 1 padding은 same으로 설정한다.
→ 13x13x384의 feature map을 얻게 되며
→ 활성화 함수로 ReLU 사용
4) 네 번째 레이어(컨볼루션)

→ 384개의 3x3x384 필터를 사용하여 컨볼루션 한다 stride 1과 padding은 same을 한다.
→ 똑같은 13x13x384의 feature map 얻음
→ 활성화 함수 ReLU 사용
5) 다섯 번째 레이어(컨볼루션)

→ 256개의 3x3x384 필터로 컨볼루션 해준다 stride와 padding은 전과 동일하다
→ 13x13x256의 feature map을 얻고
→ ReLU로 활성화
→ 3x3 maxpooling stride 2로 시행한다.
→ 6x6x256 feature map을 얻음
6) Fully-Connected Layers

- 6x6x256을 Flatten 시켜줘서 9216차원의 벡터로 만든다.
→ 4096개의 뉴런과 Dense로 연결한다.
→ ReLU로 활성화
- 마지막 레이어
→ 1000개의 뉴런으로 구성 전 단계의 4096 뉴런과 Fully Connected 해준다.
→ 1000개의 클래스로 분류하기 때문에 softmax로 활성화한다.
AlexNet에서 성능 향상을 위해 사용한 것
1. ReLU 함수

→ LeNet-5에서는 Tanh로 활성화했지만 AlexNet에서는 ReLU를 사용하였다
→ ReLU는 0에서 미분이 안된다는 단점이 있지만 학습 속도가 뛰어나며 back-propagation에서 결과도 단순하기 때문에 ReLU를 많이 사용하고 있다.
2. Overlapped Pooling
→ CNN에서 보통 Pooling은 컨볼루션으로 얻은 feature map의 크기를 줄이기 위해 사용되며 AlexNet에서는 Max Pooling을 3x3으로 사용하며 stride를 2로 하여 사용하여 출력 영상의 크기가 1/2로 줄어들게 되었다.
→ Lenet-5에서는 average Pooling을 썼지만 AlexNet에서는 MaxPooling을 씀
→ 결과적으로 top-1, top-5 에러율이 줄어들게 되었다고 한다.
3. Dropout
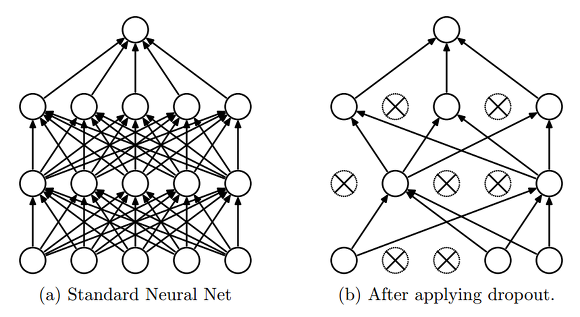
→ 과적합 (overfitting)을 막기 위한 기술인 dropout은 fully-connected layer의 뉴런 중 일부를 생략하면서 학습을 진행하는 것입니다.
→ tensorflow에서는 dropout의 확률을 정하여 학습이 진행되게 만듭니다.
→ dropout에 대한 자세한 것은 다음에 포스팅하겠습니다.
Tensorflow로 AlexNet을 구현하고 CIFAR10 데이터셋 분류
1) CIFAR10 데이터셋 로드
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
- CIFAR10 데이터셋을 로드하였고 x_train과 y_train의 모양을 확인했습니다.
x_train.shape, y_train.shape- ((50000, 32, 32, 3), (50000, 1)) 의 결과가 나왔습니다.
- 논문에서는 input의 크기가 227x227이었고 CIFAR10의 클래스가 10개 이므로 to_categorical 함수로 바꿔주었습니다.
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
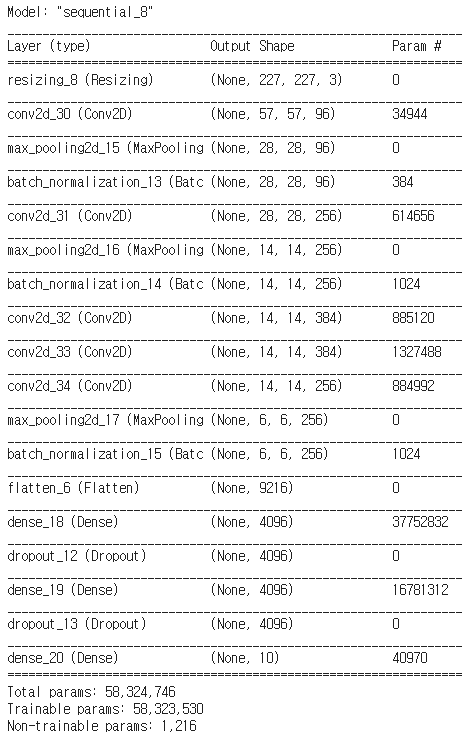
2) AlexNet 모델링
model = Sequential()
model.add(layers.experimental.preprocessing.Resizing(227, 227, interpolation="bilinear", input_shape=x_train.shape[1:]))
model.add(Conv2D(96, (11,11), strides=(4,4), activation='relu', padding='same'))
model.add(MaxPool2D((3,3), strides=2))
model.add(BatchNormalization())
model.add(Conv2D(256, (5,5), strides=1, activation='relu', padding='same'))
model.add(MaxPool2D((2, 2), strides=2))
model.add(BatchNormalization())
model.add(Conv2D(384, (3,3), strides=1, activation='relu', padding='same'))
model.add(Conv2D(384, (3,3), strides=1, activation='relu', padding='same'))
model.add(Conv2D(256, (3,3), strides=1, activation='relu', padding='same'))
model.add(MaxPool2D((3,3), strides=2))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
- 논문에서 설명한 것처럼 만들었고 input을 227x227로 resize 하여 모델링을 하였습니다.
- 마지막 Dense는 CIFAR10의 클래스가 10개이기 때문에 10으로 FC 하였고 활성화 함수로 softmax를 사용했습니다.
- model.summary() 결과
- 결과)
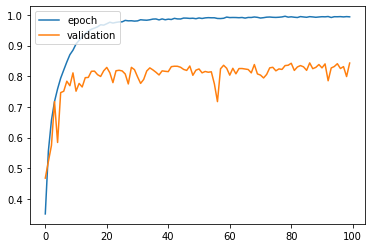
Test loss: 1.2488003969192505
Test accuracy: 0.8432000279426575
- 제가 학습을 잘못했는지 자꾸 과적합되는 모습을 보여줍니다.
- epochs를 늘리던지 데이터셋을 전처리를 하여 학습을 시키면 조금 더 잘 나올 것 같습니다.
이번 포스팅은 AlexNet에 대해 이해해 보려고 했고 Tensorflow로 구현까지 해보았습니다.
혹시나 틀린 점이나 질문이 있으시면 댓글로 남겨주세요!
감사합니다 :)
'AI > DL' 카테고리의 다른 글
| Batch Normalization (배치 정규화) 이해 (0) | 2021.08.29 |
|---|---|
| ResNet 구조 이해 및 구현 (4) | 2021.08.25 |
| VGGNet 구조 이해 및 구현 (3) | 2021.08.20 |