
출처 : 미술관에 GAN 딥러닝 실전 프로젝트
출처를 가지고 공부한 내용을 정리한 포스팅입니다.
- 이때까지 딥러닝을 공부하면서 판별 모델링에만 익숙하여 생성 모델링을 공부했을 때는 한 번에 다가오지 않는 개념이었습니다. 확률을 이용하여 생성하는 생성 모델링에 대해 이 책은 판별 모델링과 비교하여 설명하기 때문에 이해하기 좋은 것 같습니다.
생성 모델링
- 크게 본다면 확률 모델의 관점에서 생성 모델은 데이터 셋을 생성하는 방법을 기술한 것
- 모델에서 샘플링하면 새로운 데이터를 생성할 수 있다.
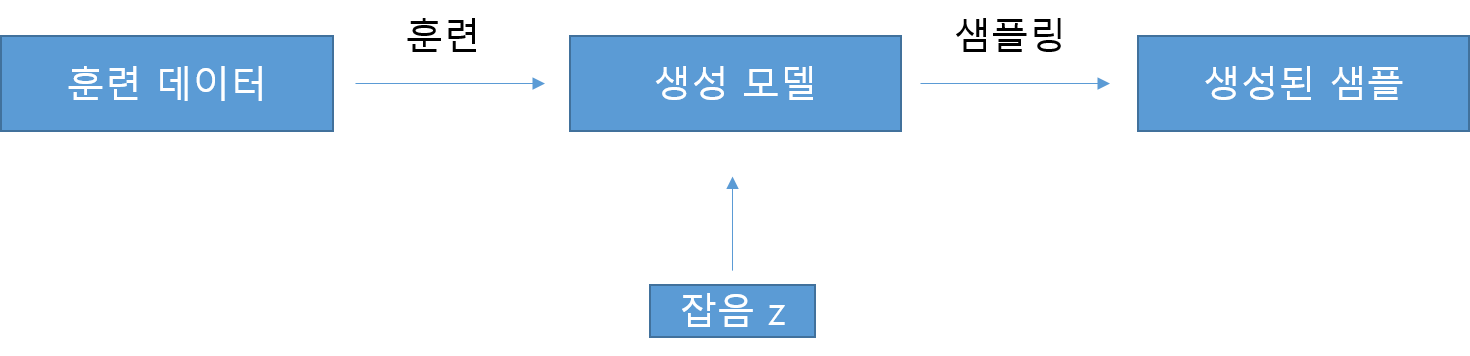
- 훈련 데이터 : 생성하려는 데이터 개체의 샘플을 많이 가진 데이터 셋
- 샘플 : 데이터 포인트 하나, 샘플은 많은 특성(feature)으로 이루어진다.
- 생성 모델은 확률적이어야 하며, 모델은 생성되는 개별의 샘플에 영향을 미칠 수 있는 확률적 요소를 포함해야 합니다.
즉, 훈련 데이터에 있는 것 같은, 새로운 특성을 생성할 수 있는 모델을 만드는 것이 목표입니다!
생성 모델링 - 판별 모델링

- 앞서 설명한 생성 모델링 과정과 비교해보세요.
- 우리가 딥러닝을 배우면서 공부했던 것은 대부분 판별 모델링일 것입니다.
이때까지는 train data와 label을 이용하여 매핑하고 학습시켜 모델을 만들고 입력을 예측하는 과정을 배웠습니다.
- 판별 모델링에서 중요한 점은 train data가 label을 가져야 한다는 점이고 이런 이유로 판별 모델을 supervised learning이라고 부르는 것입니다.
생성 모델링과 판별 모델링의 수학적 차이
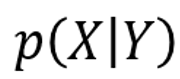
- 생성 모델링 : label, y를 통해 샘플 x일 확률을 추정합니다. 즉, 데이터셋이 레이블을 가지고 있다면 수식을 추정하는 생성 모델을 만들 수 있습니다. 생성 모델링은 샘플의 레이블에는 관심이 없지만 샘플을 발견할 확률을 추정하는 것입니다! 완벽하게 y를 판별하는 모델을 만들어도 y처럼 보이는 샘플을 만드는 방법을 알지 못한다는 것이 핵심입니다!
- 판별 모델링 : 샘플 x가 주어졌을 때 label y일 확률을 추정(예측)하는 것입니다.
그렇다면 도대체 어떻게 생성하는 것일까요?
- 이 책에서는 간단한 생성 모델링 프레임워크를 통해 생성하는 방법과 생성 성공 여부를 측정하는 방식을 알려줍니다.

- 어떤 규칙 (P_data)로 만든 데이터 셋 X를 생성했습니다.
- 생성 모델의 목표는 같은 규칙으로 생성된 것 같은 포인트를 찍는 것입니다.
- 기존의 데이터 셋 X를 가지고 모델 P_model을 구성합니다. 즉, P_model은 P_data의 추정입니다.

- P_model가 찍으려는 위치를 대강 알 수 있고 달성하려는 것이 무엇인지 이해할 수 있습니다.
생성 모델링 프레임 워크
- 샘플 데이터 셋 X가 알려지지 않은 P_data 분포로 생성됐다고 가정한다.
- P_model은 P_data를 흉내 내려고 한다. 목표 달성 시 P_model에서 샘플링하여 P_data에서 만든 것 같은 샘플을 생성할 수 있다.
- P_model의 목표
- P_data에서 만든 것 같은 샘플을 생성
- 샘플 데이터 셋 X와는 다른 데이터 샘플을 생성 -> 이미 있는 샘플을 다시 쓰지 않는다는 의미
이제 진짜 P_data가 어떤 규칙으로 만들어졌는지 파악하고 위의 프레임 워크가 어떻게 동작했는지 알아봅시다.
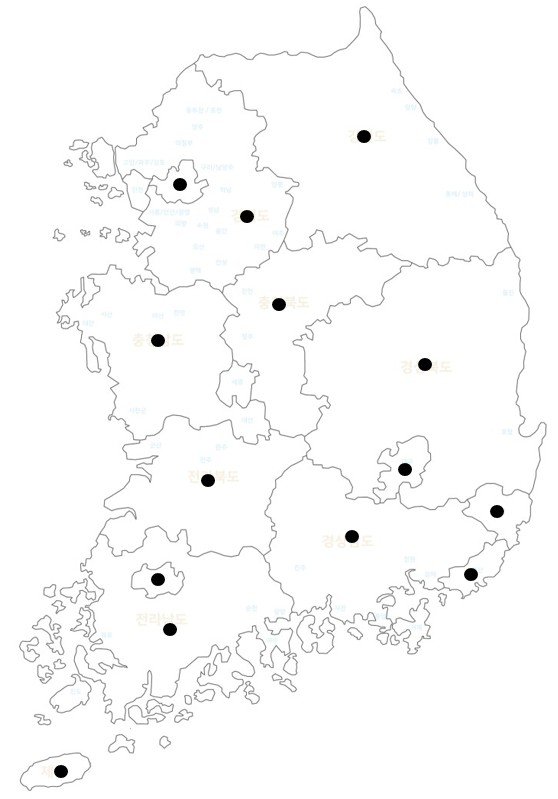
- P_data의 데이터 생성 규칙은 우리나라 지도에서 바다를 제외한 곳이 선택된 단순한 분포였습니다.
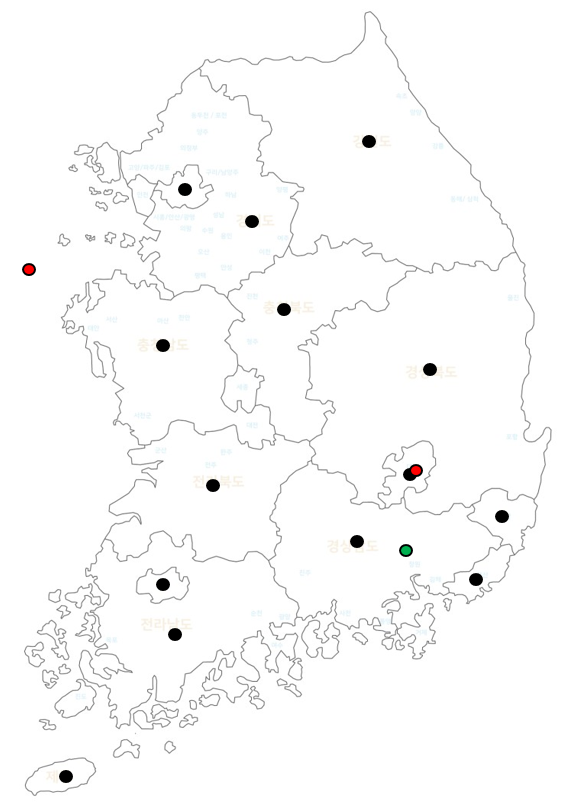
- P_model로 생성된 샘플을 보시면 바다에 찍힌 것도 있고 원래 데이터 셋과 비슷하게 찍힌 것도 있습니다.
초록색으로 찍힌 것을 제외 한 데이터들은 성공적이지 않다고 볼 수 있습니다.
- 간단한 예제를 통해 생성 모델링의 문제 해결 방법을 거시적으로 나마 알아보았고 이해가 되었습니다.
다음 포스팅은 확률적 생성 모델에 대해 알아보기 전 확률에 대해 간단하게 정리해보겠습니다.
질문이나 틀린 점이 있으면 댓글로 남겨주세요!
감사합니다 :)
'AI > GAN' 카테고리의 다른 글
| 변이형 오토인코더(Variational AutoEncoder) 이해 및 구현 (0) | 2021.08.23 |
|---|
출처 : 미술관에 GAN 딥러닝 실전 프로젝트
출처를 가지고 공부한 내용을 정리한 포스팅입니다.
- 이때까지 딥러닝을 공부하면서 판별 모델링에만 익숙하여 생성 모델링을 공부했을 때는 한 번에 다가오지 않는 개념이었습니다. 확률을 이용하여 생성하는 생성 모델링에 대해 이 책은 판별 모델링과 비교하여 설명하기 때문에 이해하기 좋은 것 같습니다.
생성 모델링
- 크게 본다면 확률 모델의 관점에서 생성 모델은 데이터 셋을 생성하는 방법을 기술한 것
- 모델에서 샘플링하면 새로운 데이터를 생성할 수 있다.
- 훈련 데이터 : 생성하려는 데이터 개체의 샘플을 많이 가진 데이터 셋
- 샘플 : 데이터 포인트 하나, 샘플은 많은 특성(feature)으로 이루어진다.
- 생성 모델은 확률적이어야 하며, 모델은 생성되는 개별의 샘플에 영향을 미칠 수 있는 확률적 요소를 포함해야 합니다.
즉, 훈련 데이터에 있는 것 같은, 새로운 특성을 생성할 수 있는 모델을 만드는 것이 목표입니다!
생성 모델링 - 판별 모델링
- 앞서 설명한 생성 모델링 과정과 비교해보세요.
- 우리가 딥러닝을 배우면서 공부했던 것은 대부분 판별 모델링일 것입니다.
이때까지는 train data와 label을 이용하여 매핑하고 학습시켜 모델을 만들고 입력을 예측하는 과정을 배웠습니다.
- 판별 모델링에서 중요한 점은 train data가 label을 가져야 한다는 점이고 이런 이유로 판별 모델을 supervised learning이라고 부르는 것입니다.
생성 모델링과 판별 모델링의 수학적 차이
- 생성 모델링 : label, y를 통해 샘플 x일 확률을 추정합니다. 즉, 데이터셋이 레이블을 가지고 있다면 수식을 추정하는 생성 모델을 만들 수 있습니다. 생성 모델링은 샘플의 레이블에는 관심이 없지만 샘플을 발견할 확률을 추정하는 것입니다! 완벽하게 y를 판별하는 모델을 만들어도 y처럼 보이는 샘플을 만드는 방법을 알지 못한다는 것이 핵심입니다!
- 판별 모델링 : 샘플 x가 주어졌을 때 label y일 확률을 추정(예측)하는 것입니다.
그렇다면 도대체 어떻게 생성하는 것일까요?
- 이 책에서는 간단한 생성 모델링 프레임워크를 통해 생성하는 방법과 생성 성공 여부를 측정하는 방식을 알려줍니다.
- 어떤 규칙 (P_data)로 만든 데이터 셋 X를 생성했습니다.
- 생성 모델의 목표는 같은 규칙으로 생성된 것 같은 포인트를 찍는 것입니다.
- 기존의 데이터 셋 X를 가지고 모델 P_model을 구성합니다. 즉, P_model은 P_data의 추정입니다.
- P_model가 찍으려는 위치를 대강 알 수 있고 달성하려는 것이 무엇인지 이해할 수 있습니다.
생성 모델링 프레임 워크
- 샘플 데이터 셋 X가 알려지지 않은 P_data 분포로 생성됐다고 가정한다.
- P_model은 P_data를 흉내 내려고 한다. 목표 달성 시 P_model에서 샘플링하여 P_data에서 만든 것 같은 샘플을 생성할 수 있다.
- P_model의 목표
- P_data에서 만든 것 같은 샘플을 생성
- 샘플 데이터 셋 X와는 다른 데이터 샘플을 생성 -> 이미 있는 샘플을 다시 쓰지 않는다는 의미
이제 진짜 P_data가 어떤 규칙으로 만들어졌는지 파악하고 위의 프레임 워크가 어떻게 동작했는지 알아봅시다.
- P_data의 데이터 생성 규칙은 우리나라 지도에서 바다를 제외한 곳이 선택된 단순한 분포였습니다.
- P_model로 생성된 샘플을 보시면 바다에 찍힌 것도 있고 원래 데이터 셋과 비슷하게 찍힌 것도 있습니다.
초록색으로 찍힌 것을 제외 한 데이터들은 성공적이지 않다고 볼 수 있습니다.
- 간단한 예제를 통해 생성 모델링의 문제 해결 방법을 거시적으로 나마 알아보았고 이해가 되었습니다.
다음 포스팅은 확률적 생성 모델에 대해 알아보기 전 확률에 대해 간단하게 정리해보겠습니다.
질문이나 틀린 점이 있으면 댓글로 남겨주세요!
감사합니다 :)
'AI > GAN' 카테고리의 다른 글
| 변이형 오토인코더(Variational AutoEncoder) 이해 및 구현 (0) | 2021.08.23 |
|---|